情報処理などコンピュータを利用する講義の増加に伴い、レポートをコンピュータで作成して提出することが多くなっています。そのため、コンピュータに関する知識が少しあれば簡単に他人のレポートを複製できてしまい、講義内容の習得率が低下しやすくなっています。
この問題を解決するために、各々のレポートが他の学生のレポートとどのくらい類似しているかを判定するシステムを構築しました。このシステムを利用することで、また、このシステムの存在を知らせるだけでも、レポートの複製という行為の無意味さを学生に気づかせ、学生のやる気を促すことができます。
当システムは文書検索の概念を用いて、以下のような流れで類似度判定を行います。(単純な類似度判定の例)
- レポートを一つの文書とみなし、形態素に分解します。
- 形態素の中から、実際に類似度判定に用いる形態素を抽出します。
- 形態素ごとにtfおよびidfを取得します。
- tf・idfを用いて文書ベクトルを作成し、ベクトル間のなす角の大きさを変換して類似度とし、似ているかどうかを判定します。
|
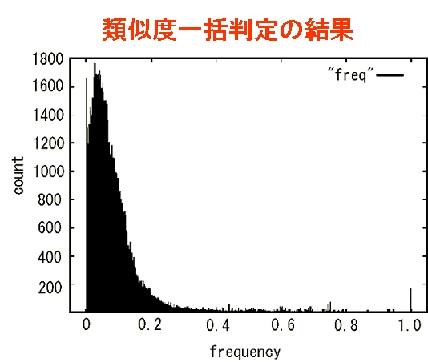
右図は、実際に講義で提出されたレポート639部に対して、本システムで類似度を判定した結果です。
類似度0.0〜0.1にデータが集中しているのは、類似しているレポートが全体的に少ないことを示しています。類似度が1.0と判定されたレポートは170組でした。これらのレポートに関しては「あまりに似すぎていて、写したと考えられる」と判定できます。
|
|
![]](http://www.cvl.cs.chubu.ac.jp/lab/object/menu/on_right.gif)


![]](http://www.cvl.cs.chubu.ac.jp/lab/object/menu/sub_on_right.gif)










